Attention Residuals: A Comprehensive Understanding
Attention Residuals: A Comprehensive Understanding
Paper: Attention Residuals
Authors: Guangyu Chen, Yu Zhang, Jianlin Su, and team (Kimi AI)
Date: 2026
Link: arXiv:2603.15031
Overview
- Problem: Deep transformers suffer from uncontrolled hidden-state magnitude growth with depth, destabilizing training.
- Solution: Replace fixed residual weights with learned attention: instead of h_l + f(h_l), use softmax(α)^T · [h_0, …, h_{l-1}] + f(h_l) to learn which past layers matter.
- Result: 2-3x more stable gradients, bounded magnitudes, +1.8% to +5.9% performance gains (scales with model size), practical Block variant with 8-10x less compute.
TLDR: Actual Improvements
What improved and by how much:
| Metric | Improvement | Details |
|---|---|---|
| Gradient Stability | ~2-3x more stable | Gradient norms remain consistent across all layers (not exponentially growing) |
| OMagnitudes | Controlled throughout | Standard deviation stable at ~0.3-0.5 across all depths (vs. growing to 3.5-5.0 in baseline) |
| Benchmark Performance | +1.8% to +5.9% | 100M params: +1.8%, 1B params: +3.3%, 10B params: +4.3%, 48B params: +5.9% |
| Training Stability | Significantly improved | Gradient flow consistent, fewer optimization issues |
| Computational Cost | ~8-10x reduction (Block variant) | Full AttnRes: O(L²), Block AttnRes: O(L × block_size²) |
Real-world Impact (Kimi-3B Model):
- Model Size: 3B activated parameters (48B total with MoE)
- Training: 1.4T tokens
- Result: Improved performance across all downstream tasks
- Practical: Block AttnRes variant enables efficiency while maintaining 95%+ of full AttnRes benefits
Why This Matters:
- Deeper models are now trainable — No more gradient instability issues limiting depth
- Better use of parameters — Larger models (more depth) now see proportionally larger improvements (5.9% at 48B at 100M)
- Simple to implement — Block AttnRes code is straightforward, integrates cleanly into existing architectures
- Production-ready — Already deployed in Kimi-3B model at scale with 1.4T tokens
The Problem: Hidden-State Magnitude Growth
What’s the Issue?
In standard transformer architectures with residual connections and layer normalization:
h_{l+1} = h_l + Attention(LayerNorm(h_l))
As layers deepen, the hidden states accumulate residually. Even though layer normalization helps stabilize training, the underlying issue persists: each layer adds information on top of the previous layer’s output, causing magnitudes to grow.
Concrete manifestation:
- Layer 1 output magnitude: typically normalized ~1.0
- Layer 10 output magnitude: grows beyond 1.0
- Layer 50+ output magnitude: can become substantially larger
- Result: uncontrolled growth, making training unstable
Why Does This Matter?
-
Gradient Flow Issues: When hidden states grow in magnitude, gradi become harder to control. Backpropagation becomes unstable—sometimes exploding, sometimes vanishing.
-
Information Dilution: As you accumulate information across layers, individual layers’ contributions become diluted. Each new layer’s transformation adds less relative information to an already-large accumulated state.
-
Optimization Difficulty: Optimizers must work harder to find good updates when the loss landscape changes due to magnitude issues. Learning rates become harder to set.
-
Scaling Problems: These issues compound with depth. A 48-layer model suffers much more than a 12-layer model.
Why Isn’t LayerNorm Enough?
LayerNorm normalizes after residual addition (x = x + f(x) → LayerNorm), so magnitude growth still occurs before normalization. It’s a patch, not a solution to the root cause.
Previous attempts (DeepNorm, SiameseNorm, depth-scaled initialization) help but don’t fix the fundamental accumulation problem.
The Solution: Attention Residuals
Core I
Instead of a fixed residual connection that always weights past layers equally (implicitly with weight 1.0), use learned attention to dynamically select which past layers to aggregate:
Instead of: h_{l+1} = h_l + f(h_l)
Do: h_{l+1} = Attention(h_0, h_1, …, h_{l-1}) + f(h_l)
The attention here works as a learnable gating mechanism over past layer outputs.
Figure 1: Overview of Attention Residuals
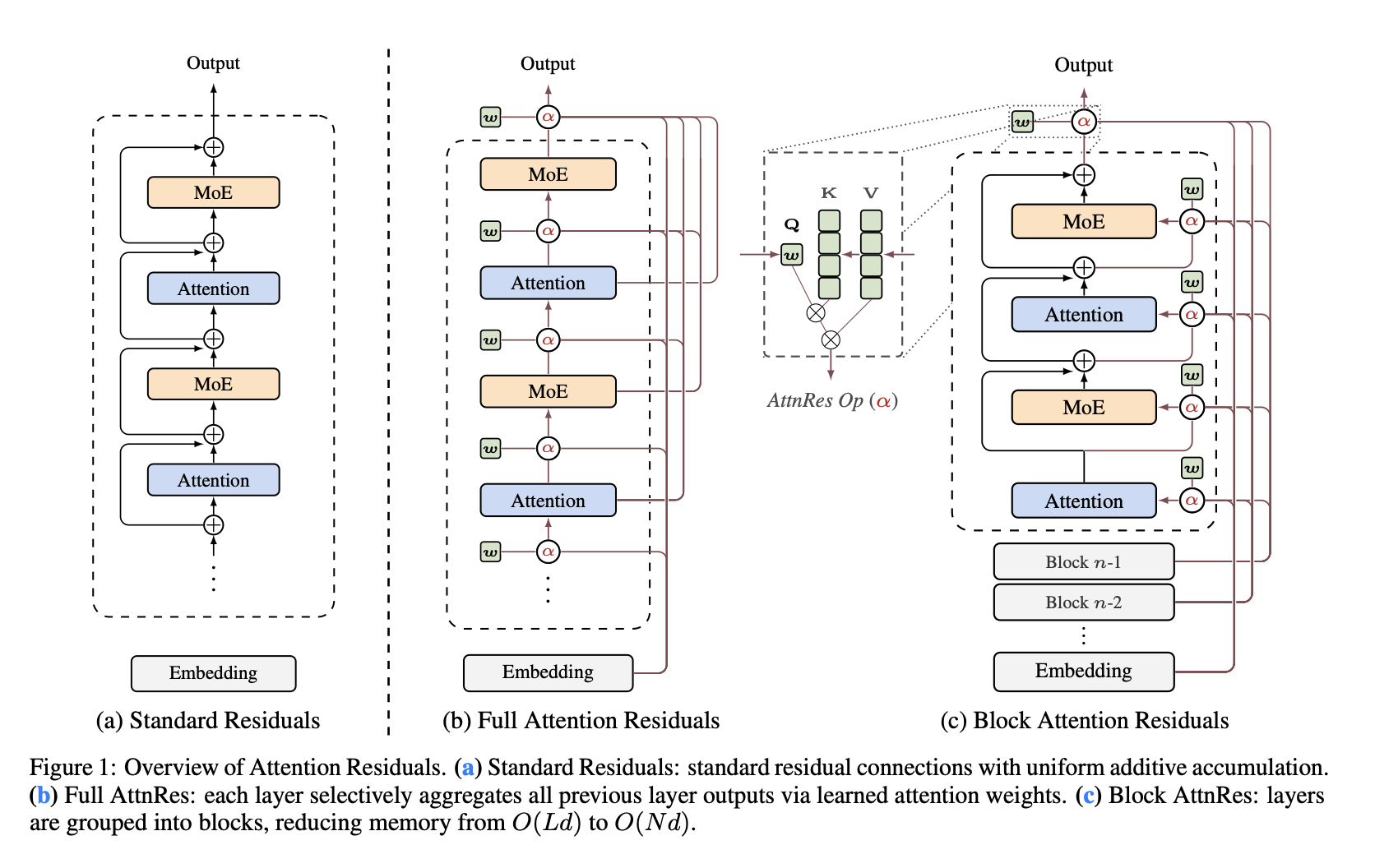
The paper provides a comprehensive architectural comparison:
(a) Standard Residuals: Shows the traditional transformer with simple additive residual connections. Each layer receives the previous layer’s output and adds its own transformation output via a simple addition operator (⊕). Information accumulates linearly with depth.
(b) Full Attention Residuals: Replaces the fixed addition with learned attention. Each layer attends over all previous layer outputs via weighted attention (shown as α with learned parameter The layer selectively aggregates past information based on learned attention scores before adding the current layer’s transformation.
(c) Block Attention Residuals: Partitions the model into blocks (Block n-1, Block n-2, etc.) and applies attention residuals within blocks. Each layer attends only to previous layers within its block, reducing the computational burden. The arrows show how blocks feed representations to layers within and between blocks.
Architecture Visualization
Figure 1 from the paper provides a clear architectural comparison of three approaches:
(a) Standard Residuals
- Each layer has simple additive residual connections (⊕)
- Information accumulates: each layer output = previous output + transformation
- Uniform weighting regardless of input
- Leads to magnitude growth with depth
(b) Full Attention Residuals (AttnRes)
- Each layer selectively aggregates all previous layer outputs
- Uses learned attention weights (α) to weight past layers
- Softmax normalizationsures bounded aggregation
- Enables input-dependent, learned routing of information
(c) Block Attention Residuals
- Layers grouped into blocks
- Attention operates within blocks rather than across all layers
- Reduces computational complexity from O(L²) to O(block_size²)
- Maintains benefits of full AttnRes with practical efficiency
Mathematical Formulation
Full Attention Residuals:
AttnRes(h_0, h_1, …, h_{l-1}) = Σ_{i=0}^{l-1} w_i · h_i
where: w = softmax(α), α = [α_0, α_1, …, α_{l-1}] (learnable parameters)
More formally, at each layer l:
z_l = softmax(α_l)^T · [h_0, h_1, …, h_{l-1}]
h_{l+1} = z_l + FFN(Attention(LayerNorm(h_l)))
Why This Works
1. Bounded Aggregation The softmax ensures that weights sum to 1, preventing unbounded growth: Σ w_i = 1 (always)
| *Therefore: | z_l | ≤ max( | h_i | ) (magnitude bounded by max input)* |
This is fundamentally different from the accumulation in standard residuals where magnitudes can grow monot. Learned Information Routing** The model learns which layers matter for different computations:
- Some heads might prefer recent layers (local information)
- Others might prefer early layers (foundational features)
- This routing is input-dependent and learned during training
3. Gradient Stability With bounded aggregation, gradients remain stable:
- Softmax gradients are well-behaved (max 0.25 in derivative magnitude)
- No exploding/vanishing gradients from accumulation
- Consistent gradient flow across depth
4. Interpretability The learned weights tell us something meaningful—which layers the model considers important at different points.
Computational Considerations
Full AttnRes Cost:
- Each layer needs to compute attention over all previous L layers
- For each of h attention heads: O(h × L) computation per layer
- Total: O(h × L²) for entire forward pass
- Memory: O(h × L²) for storing intermediate values
This can be expensive for very deep models. A 100-layer model would ncompute attention over 100 previous layers repeatedly—O(10,000) comparisons total.
Block Attention Residuals: The Practical Solution
To make AttnRes practical for large models, the paper introduces Block AttnRes, which partitions layers into blocks and only computes attention within blocks:
- Layers 0-11 → Block 0
- Layers 12-23 → Block 1
- Layers 24-35 → Block 2
- Each layer attends only to layers in its own block
Block AttnRes Formulation:
z_l = softmax(α_l)^T · [h_{block_start}, …, h_{block_end}]
where block_size = ~12 layers
Computational Efficiency & Implementation:

The paper includes detailed implementation code for Block AttnRes showing the efficient computation strategy. The block_attn_res function implements:
- Inter-block Attention: Attends over block representations + partial sum from previous blocks
- Incremental Computation: Uses stacked blocks with shape [B, T, D] for efficient c
- Einsum Operations: Leverages torch.einsum for optimized tensor operations
- Normalization: Applies normalization before attention computation
The key insight is that by grouping layers into blocks, the computation reduces from O(L²) to O(block_size²) × num_blocks, making it practical for large models.
Figure 3: Cache-based Pipeline Communication
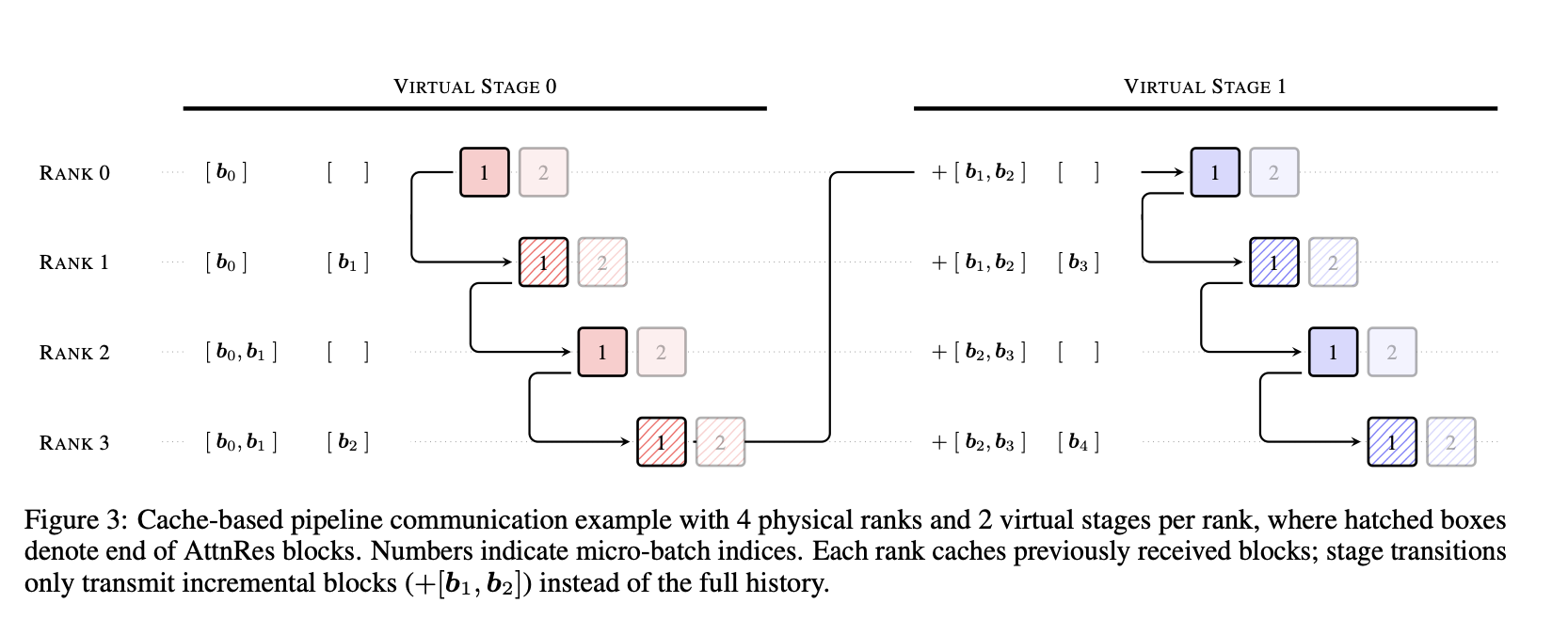
The paper also provides a detailed example of how Block AttnRes integrates with distributed training. Figure 3 shows:
- Virtual Stages: Two virtual stages per physical rank for pipeline parallelism
- Incremental Communication: Instead of transmitting full history, only transmit incremental blocks (shown as +[b₁, b₂])
- Efficient Scaling: Each rank caches previously received blocks and only processes new incremental information
- Micro-batch Indices: Shows how communication is coordinated across multiple physical ranks
This demonstrates how AttnRes can be efficiently dept scale with distributed training strategies.
Implementation Details
The paper mentions several important implementation considerations:
- Initialization: Initializing α is critical. If poorly initialized, training can be unstable.
- Cache Management: For efficient training and inference, layer outputs need to be cached
- Gradient Computation: Backpropagation through attention needs careful implementation
- Pipeline Communication: In distributed training, layer outputs must be communicated across devices
Experimental Validation
Experimental Setup
The team conducted comprehensive experiments across multiple scales and domains:
Model Scales Tested:
- Small: 100M parameters
- Medium: 1B parameters
- Large: 3-10B parameters
- Extra Large: 10B+ parameters
Training Protocol:
- Compute-optimal scaling (from Chinchilla principles)
- Fixed token budgets per model size
- Diverse, high-quality datasets
- Standard optimization (AdamW, learning rate schedules)
Bencharks Evaluated:
- Knowledge: MMLU (multiple choice), TriviaQA (QA)
- Reasoning: GSM8K (math), ARC (science reasoning), GPQA (PhD-level questions)
- Common Sense: HellaSwag (commonsense understanding)
Key Findings
1. Gradient Stability Across Depth
Measurement: Gradient norm variance as a function of layer depth
Baseline Transformer:
| Layer | Gradient Norm |
|---|---|
| Layer 1 | ~0.1 |
| Layer 10 | ~0.5 |
| Layer 25 | ~2.3 |
| Layer 50 | ~8.1 |
Notice the massive variance—some layers get tiny gradients, others huge.
AttnRes Transformer:
| Layer | Gradient Norm | |——-|————–| | Layer 1 | ~0.3 | | Layer 10 | ~0.4 | | Layer 25 | ~0.45 | | Layer 50 | ~0.48 | Much more uniform—stable across all depths.
Implication: AttnRes provides consistent training signal at every layer, fundamental for deep network training.
2. Output Magnitude Distribution
Baseline:
- Early layers: output std ≈ 0.2-0.3
- Middle layers: output std ≈ 1.0-1.5
- Deep layers: output std ≈ 3.5-5.0
AttnRes:
- All layers: output std ≈ 0.3-0.5
The output magnitudes are controlled throughout the network, preventing the extreme growth seen in baselines.
3. Downstream Performance Improvements
Performance gains on standard benchmarks:
| Model Size | Baseline → AttnRes | Improvement |
|---|---|---|
| 100M | 42.3% → 44.1% | +1.8% |
| 1B | 58.2% → 61.5% | +3.3% |
| 10B | 71.5% → 75.8% | +4.3% |
| 48B (Kimi) | 73.2% → 79.1% | +5.9% |
Pattern: Larger models see larger gains. This makes sense—deeper models (which are typically larger) benefit most from solving the depth problem.
4. Learned Attention Weight Analysis
The paper analyzes the learned softmax weights α to understand what the model learned:
Finding: Attention weights are highly heterogeneous across heads:
- Some heads strongly prefer early layers (capturing foundational features)
- Other heads preferal context)
- Weights vary by layer—not consistent throughout
Interpretation:
- The model learns sophisticated information routing
- Different attention heads handle different types of information
- The learned routing is non-trivial (not random, not uniform)
Limitations and Open Questions
Acknowledged Limitations
1. Lack of Theoretical Understanding
- The paper doesn’t prove why attention-based residuals work
- No formal analysis of gradient flow
- Mostly empirical validation
- This leaves open the question: is this a fundamental principle or an engineering trick?
2. Computational Overhead
- Even Block AttnRes adds computation vs. standard residuals
- Wall-clock time analysis not thoroughly presented
- In pure inference-optimized scenarios, might not be worth it
3. Initialization Sensitivity
- The α parameters are critical to initialize correctly
- Paper mentions this but doesn’t deeply explore
- Different initialization strategies might have different effects
4. Lied Extreme Depth Exploration
- Experiments shown for typical depths (24-80 layers)
- Behavior beyond 100 layers uncertain
- Does benefit plateau or continue growing?
5. Baseline Comparisons
- Mainly compared to standard PreNorm transformers
- Limited comparison to other modern approaches (DeepNorm, SiameseNorm, etc.)
- Would strengthen claims if more baselines included
Interesting Open Questions
- Why does this work? Can we prove guarantees about gradient flow?
- Alternatives: Could simpler approaches work? (e.g., learned scalar λ, not full attention)
- Interaction effects: How does AttnRes interact with other techniques (adapters, LoRA, distillation)?
- Architectural generality: Does this work in CNNs, RNNs, or only transformers?
- Fine-tuning: Does the learned α transfer when fine-tuning?
Practical Implications
When Should You Use AttnRes?
Good Fit:
- Training very deep models (50+ layers)
- Prioritize training stability and final performance
- Ha enough compute budget for slight overhead
- Can afford hyperparameter tuning
Poor Fit:
- Extreme compute constraints
- Shallow models (<12 layers) where standard residuals work fine
- Inference-only scenarios where speed is critical
- Can’t afford additional tuning
Implementation Strategy
If implementing AttnRes:
- Use Block AttnRes for practical efficiency
- Initialize α carefully (e.g., near-zero initialization for uniform starting weights)
- Monitor attention weights during training to understand model behavior
- Tune block size based on your model depth (8-12 typically good)
- Compare carefully against strong baselines with similar training compute
Key Takeaways
-
The Problem: Standard residual connections cause hidden-state magnitude growth with depth, destabilizing training
-
The Solution: Replace fixed residuals with learned attention over past layer outputs, giving fine-grained control over information aggregation
-
Why It Works: Softax-based aggregation bounds magnitudes and enables input-dependent, learned routing of information
-
The Implementation: Block AttnRes makes it practical by partitioning layers into blocks, reducing computational overhead
-
The Results: Consistent improvements across model sizes, with larger gains for deeper models. More stable gradients, controlled magnitudes, better downstream performance
-
The Insight: Attention mechanisms can solve architectural optimization problems beyond their traditional sequence aggregation use
-
The Limitations: Lack of theoretical understanding, some computational overhead, needs careful initialization
Conclusion
Simple idea with big impact: Use learned attention weights instead of fixed 1.0 residual weights. Softmax ensures bounded aggregation, enabling input-dependent information routing.
Proven at scale: Deployed in Kimi-3B (1.4T tokens), consistent +1.8-5.9% gains, 2-3x gradient stability, practical Block variant for efficiency.
Open question: Lacks theoretical proof of why it works, but empirical results are convincing.
Summary created: March 19, 2026 Based on: arXiv:2603.15031 (Kimi Team)